

استخراج معنایی مجموعهباز: خط تولید Grounded-SAM، CLIP و DINOv2
جدول پیوندها
خلاصه و 1 مقدمه
-
کارهای مرتبط
2.1. ناوبری بینایی و زبان
2.2. درک معنایی صحنه و تقسیمبندی نمونه
2.3. بازسازی صحنه سه بعدی
-
روششناسی
3.1. جمعآوری دادهها
3.2. اطلاعات معنایی مجموعه باز از تصاویر
3.3. ایجاد نمایش سه بعدی مجموعه باز
3.4. ناوبری هدایت شده با زبان
-
آزمایشها
4.1. ارزیابی کمی
4.2. نتایج کیفی
-
نتیجهگیری و کارهای آینده، بیانیه افشا و منابع
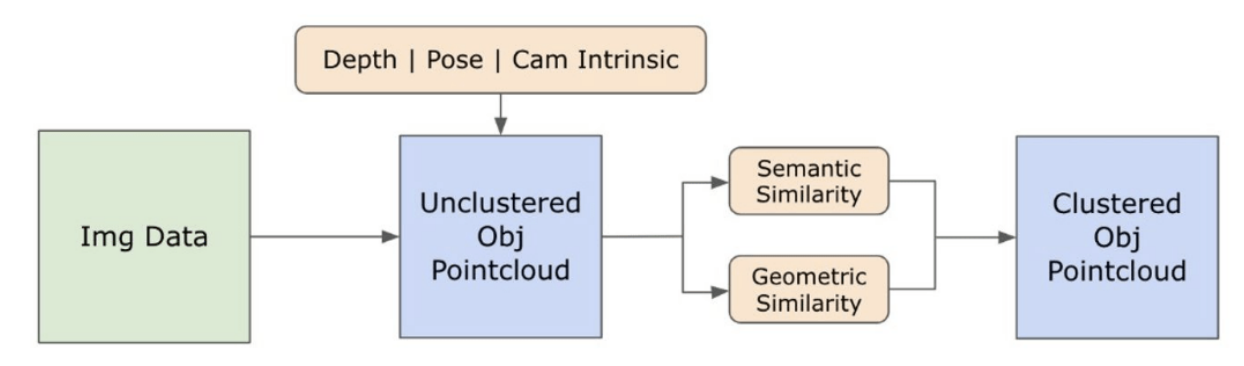
3.2. اطلاعات معنایی مجموعه باز از تصاویر
\ 3.2.1. تشخیص معنایی مجموعه باز و ماسکهای نمونه
\ مدل Segment Anything (SAM) [21] که اخیراً منتشر شده است، به دلیل قابلیتهای پیشرفته تقسیمبندی، محبوبیت قابل توجهی در میان محققان و متخصصان صنعتی به دست آورده است. با این حال، SAM تمایل به تولید تعداد بیش از حد ماسکهای تقسیمبندی برای یک شیء یکسان دارد. ما مدل Grounded-SAM [32] را برای روششناسی خود برای رفع این مشکل انتخاب کردیم. این فرآیند شامل تولید مجموعهای از ماسکها در سه مرحله است، همانطور که در شکل 2 نشان داده شده است. در ابتدا، مجموعهای از برچسبهای متنی با استفاده از مدل Recognizing Anything (RAM) [33] ایجاد میشود. سپس، کادرهای محدودکننده مربوط به این برچسبها با استفاده از مدل Grounding DINO [25] ایجاد میشوند. تصویر و کادرهای محدودکننده سپس به SAM وارد میشوند تا ماسکهای تقسیمبندی مستقل از کلاس برای اشیاء دیده شده در تصویر تولید شوند. ما توضیح دقیقی از این رویکرد در زیر ارائه میدهیم، که به طور موثر مشکل تقسیمبندی بیش از حد را با ترکیب بینشهای معنایی از RAM و Grounding-DINO کاهش میدهد.
\ مدل RAM [33] تصویر RGB ورودی را پردازش میکند تا برچسبگذاری معنایی شیء تشخیص داده شده در تصویر را تولید کند. این یک مدل پایه قوی برای برچسبگذاری تصویر است که توانایی قابل توجه zero-shot در شناسایی دقیق دستههای مختلف رایج را نشان میدهد. خروجی این مدل هر تصویر ورودی را با مجموعهای از برچسبها که دستههای شیء در تصویر را توصیف میکنند، مرتبط میکند. فرآیند با دسترسی به تصویر ورودی و تبدیل آن به فضای رنگی RGB شروع میشود، سپس برای متناسب شدن با نیازهای ورودی مدل تغییر اندازه داده میشود، و در نهایت آن را به یک تنسور تبدیل میکند، که آن را با تحلیل توسط مدل سازگار میکند. پس از این، مدل RAM برچسبها یا تگهایی را تولید میکند که اشیاء یا ویژگیهای مختلف موجود در تصویر را توصیف میکنند. یک فرآیند فیلتراسیون برای پالایش برچسبهای تولید شده به کار گرفته میشود، که شامل حذف کلاسهای ناخواسته از این برچسبها است. به طور خاص، تگهای نامربوط مانند "دیوار"، "کف"، "سقف" و "دفتر" حذف میشوند، همراه با سایر کلاسهای از پیش تعریف شده که برای زمینه مطالعه غیرضروری تلقی میشوند. علاوه بر این، این مرحله امکان افزایش مجموعه برچسب با هر کلاس مورد نیاز که در ابتدا توسط مدل RAM تشخیص داده نشده است را فراهم میکند. در نهایت، تمام اطلاعات مربوطه در یک قالب ساختاریافته جمعآوری میشوند. به طور خاص، هر تصویر در دیکشنری img_dict فهرستبندی میشود، که مسیر تصویر را همراه با مجموعه برچسبهای تولید شده ثبت میکند، و بدین ترتیب یک مخزن قابل دسترسی از دادهها برای تحلیلهای بعدی را تضمین میکند.
\ پس از برچسبگذاری تصویر ورودی با برچسبهای تولید شده، جریان کار با فراخوانی مدل Grounding DINO [25] پیشرفت میکند. این مدل در زمینهسازی عبارات متنی به مناطق خاصی در یک تصویر تخصص دارد، و به طور موثر اشیاء هدف را با کادرهای محدودکننده مشخص میکند. این فرآیند اشیاء را در تصویر شناسایی و به صورت فضایی مکانیابی میکند، و زمینه را برای تحلیلهای دقیقتر فراهم میکند. پس از شناسایی و مکانیابی اشیاء از طریق کادرهای محدودکننده، مدل Segment Anything (SAM) [21] به کار گرفته میشود. عملکرد اصلی مدل SAM تولید ماسکهای تقسیمبندی برای اشیاء درون این کادرهای محدودکننده است. با انجام این کار، SAM اشیاء فردی را جدا میکند، و امکان تحلیل دقیقتر و خاص شیء را با جداسازی موثر اشیاء از پسزمینه و یکدیگر در تصویر فراهم میکند.
\ در این نقطه، نمونههای اشیاء شناسایی، مکانیابی و جدا شدهاند. هر شیء با جزئیات مختلفی شناسایی میشود، از جمله مختصات کادر محدودکننده، یک اصطلاح توصیفی برای شیء، احتمال یا نمره اطمینان وجود شیء که در لاجیتها بیان شده است، و ماسک تقسیمبندی. علاوه بر این، هر شیء با ویژگیهای جاسازی CLIP و DINOv2 مرتبط است، که جزئیات آن در زیربخش بعدی شرح داده شده است.
\ 3.2.2. استخراج جاسازی معنایی
\ برای بهبود درک ما از جنبههای معنایی نمونههای شیء که در تصاویر ما تقسیمبندی و ماسک شدهاند، ما از دو مدل، CLIP [9] و DINOv2 [10]، برای استخراج نمایشهای ویژگی از تصاویر برش داده شده هر شیء استفاده میکنیم. یک مدل که منحصراً با CLIP آموزش دیده است، به درک معنایی قوی از تصاویر دست مییابد اما نمیتواند عمق و جزئیات پیچیده درون آن تصاویر را تشخیص دهد. از طرف دیگر، DINOv2 عملکرد برتری در درک عمق نشان میدهد و در شناسایی روابط ظریف سطح پیکسل در سراسر تصاویر برتری دارد. به عنوان یک Vision Transformer خودنظارتی، DINOv2 میتواند جزئیات ویژگی ظریف را بدون اتکا به دادههای حاشیهنویسی شده استخراج کند، که آن را به ویژه در شناسایی روابط فضایی و سلسله مراتب درون تصاویر موثر میسازد. به عنوان مثال، در حالی که مدل CLIP ممکن است در تمایز بین دو صندلی با رنگهای مختلف، مانند قرمز و سبز، مشکل داشته باشد، قابلیتهای DINOv2 اجازه میدهد چنین تمایزهایی به وضوح ایجاد شوند. در نتیجه، این مدلها هم ویژگیهای معنایی و هم بصری اشیاء را ثبت میکنند، که بعداً برای مقایسههای شباهت در فضای سه بعدی استفاده میشوند.
\ 
\ مجموعهای از مراحل پیشپردازش برای پردازش تصاویر با مدل DINOv2 پیادهسازی شده است. این موارد شامل تغییر اندازه، برش مرکزی، تبدیل تصویر به یک تنسور، و نرمالسازی تصاویر برش داده شده که توسط کادرهای محدودکننده مشخص شدهاند، میباشد. تصویر پردازش شده سپس به مدل DINOv2 همراه با برچسبهای شناسایی شده توسط مدل RAM وارد میشود تا ویژگیهای جاسازی DINOv2 را تولید کند. از طرف دیگر، هنگام کار با مدل CLIP، مرحله پیشپردازش شامل تبدیل تصویر برش داده شده به یک قالب تنسور سازگار با CLIP، و سپس محاسبه ویژگیهای جاسازی است. این جاسازیها بسیار مهم هستند زیرا آنها ویژگیهای بصری و معنایی اشیاء را در بر میگیرند، که برای درک جامع اشیاء در صحنه ضروری هستند. این جاسازیها بر اساس نرم L2 خود نرمالسازی میشوند، که بردار ویژگی را به یک طول واحد استاندارد تنظیم میکند. این مرحله نرمالسازی امکان مقایسههای سازگار و منصفانه در سراسر تصاویر مختلف را فراهم میکند.
\ در فاز پیادهسازی این مرحله، ما روی هر تصویر در دادههای خود تکرار میکنیم و روشهای زیر را اجرا میکنیم:
\ (1) تصویر به منطقه مورد نظر با استفاده از مختصات کادر محدودکننده ارائه شده توسط مدل Grounding DINO برش داده میشود، که شیء را برای تحلیل دقیق جدا میکند.
\ (2) جاسازیهای DINOv2 و CLIP را برای تصویر برش داده شده تولید میکنیم.
\ (3) در نهایت، جاسازیها همراه با ماسکها از بخش قبلی ذخیره میشوند.
\ با تکمیل این مراحل، ما اکنون نمایشهای ویژگی دقیق برای هر شیء داریم، که مجموعه دادههای ما را برای تحلیل و کاربرد بیشتر غنی میکند.
\
:::info نویسندگان:
(1) لاکش نانوانی، موسسه بینالمللی فناوری اطلاعات، حیدرآباد، هند؛ این نویسنده به طور مساوی در این کار مشارکت داشته است؛
(2) کوماراادیتیا گوپتا، موسسه بینالمللی فناوری اطلاعات، حیدرآباد، هند؛
(3) آدیتیا ماتور، موسسه بینالمللی فناوری اطلاعات، حیدرآباد، هند؛ این نویسنده به طور مساوی در این کار مشارکت داشته است؛
(4) سوایام آگراوال، موسسه بینالمللی فناوری اطلاعات، حیدرآباد، هند؛
(5) ای.اچ. عبدالحافظ، دانشگاه حسن کالیونجو، شاهینبی، غازیعنتاب، ترکیه؛
(6) کی. مادهاوا کریشنا، موسسه بینالمللی فناوری اطلاعات، حیدرآباد، هند.
:::
:::info این مقاله در arxiv تحت مجوز CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) در دسترس است.
:::
\
محتوای پیشنهادی

کسانی که XRP را از دست دادند اکنون به Apeing ($APEING) به عنوان یکی از ارزهای دیجیتال بعدی سال ۲۰۲۵ برای رسیدن به ۱ دلار چشم دوختهاند

کمیسیون بورس و اوراق بهادار راهنمای نگهداری ارز دیجیتال برای سرمایهگذاران خرد را منتشر کرد
