

Estrazione Semantica Open-Set: Pipeline Grounded-SAM, CLIP e DINOv2
Tabella dei Link
Astratto e 1 Introduzione
-
Lavori Correlati
2.1. Navigazione Visione-e-Linguaggio
2.2. Comprensione Semantica della Scena e Segmentazione delle Istanze
2.3. Ricostruzione della Scena 3D
-
Metodologia
3.1. Raccolta Dati
3.2. Informazioni Semantiche Open-set dalle Immagini
3.3. Creazione della Rappresentazione 3D Open-set
3.4. Navigazione Guidata dal Linguaggio
-
Esperimenti
4.1. Valutazione Quantitativa
4.2. Risultati Qualitativi
-
Conclusione e Lavori Futuri, Dichiarazione di divulgazione e Riferimenti
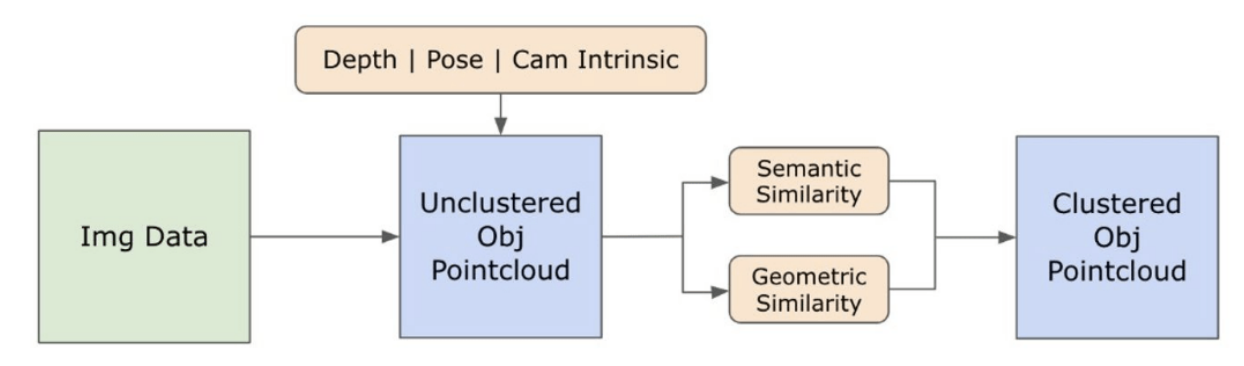
3.2. Informazioni Semantiche Open-set dalle Immagini
\ 3.2.1. Rilevamento di Maschere Semantiche e di Istanze Open-set
\ Il modello Segment Anything (SAM) [21] recentemente rilasciato ha guadagnato notevole popolarità tra ricercatori e professionisti industriali grazie alle sue capacità di segmentazione all'avanguardia. Tuttavia, SAM tende a produrre un numero eccessivo di maschere di segmentazione per lo stesso oggetto. Adottiamo il modello Grounded-SAM [32] per la nostra metodologia per affrontare questo problema. Questo processo comporta la generazione di un insieme di maschere in tre fasi, come illustrato nella Figura 2. Inizialmente, viene creato un insieme di etichette di testo utilizzando il modello Recognizing Anything (RAM) [33]. Successivamente, vengono create le bounding box corrispondenti a queste etichette utilizzando il modello Grounding DINO [25]. L'immagine e le bounding box vengono quindi inserite in SAM per generare maschere di segmentazione agnostiche rispetto alla classe per gli oggetti visibili nell'immagine. Forniamo una spiegazione dettagliata di questo approccio di seguito, che mitiga efficacemente il problema della sovra-segmentazione incorporando intuizioni semantiche da RAM e Grounding-DINO.
\ Il modello RAM [33] elabora l'immagine RGB di input per produrre l'etichettatura semantica dell'oggetto rilevato nell'immagine. È un modello fondamentale robusto per il tagging delle immagini, che mostra una notevole capacità zero-shot nell'identificare con precisione varie categorie comuni. L'output di questo modello associa ogni immagine di input con un insieme di etichette che descrivono le categorie di oggetti nell'immagine. Il processo inizia con l'accesso all'immagine di input e la conversione nello spazio colore RGB, quindi ridimensionata per adattarsi ai requisiti di input del modello, e infine trasformandola in un tensore, rendendola compatibile con l'analisi del modello. Successivamente, il modello RAM genera etichette, o tag, che descrivono i vari oggetti o caratteristiche presenti all'interno dell'immagine. Viene impiegato un processo di filtrazione per raffinare le etichette generate, che comporta la rimozione di classi indesiderate da queste etichette. In particolare, tag irrilevanti come "muro", "pavimento", "soffitto" e "ufficio" vengono scartati, insieme ad altre classi predefinite ritenute non necessarie per il contesto dello studio. Inoltre, questa fase consente l'aumento del set di etichette con eventuali classi richieste non inizialmente rilevate dal modello RAM. Infine, tutte le informazioni pertinenti vengono aggregate in un formato strutturato. In particolare, ogni immagine è catalogata all'interno del dizionario img_dict, che registra il percorso dell'immagine insieme all'insieme di etichette generate, garantendo così un repository accessibile di dati per l'analisi successiva.
\ Dopo il tagging dell'immagine di input con le etichette generate, il flusso di lavoro progredisce invocando il modello Grounding DINO [25]. Questo modello si specializza nel collegare frasi testuali a regioni specifiche all'interno di un'immagine, delineando efficacemente gli oggetti target con bounding box. Questo processo identifica e localizza spazialmente gli oggetti all'interno dell'immagine, gettando le basi per analisi più granulari. Dopo aver identificato e localizzato gli oggetti tramite bounding box, viene impiegato il Segment Anything Model (SAM) [21]. La funzione principale del modello SAM è generare maschere di segmentazione per gli oggetti all'interno di queste bounding box. Così facendo, SAM isola i singoli oggetti, consentendo un'analisi più dettagliata e specifica per oggetto separando efficacemente gli oggetti dal loro sfondo e tra loro all'interno dell'immagine.
\ A questo punto, le istanze degli oggetti sono state identificate, localizzate e isolate. Ogni oggetto è identificato con vari dettagli, incluse le coordinate della bounding box, un termine descrittivo per l'oggetto, la probabilità o il punteggio di confidenza dell'esistenza dell'oggetto espresso in logit, e la maschera di segmentazione. Inoltre, ogni oggetto è associato a caratteristiche di embedding CLIP e DINOv2, i cui dettagli sono elaborati nella sottosezione seguente.
\ 3.2.2. L'Estrazione dell'Embedding Semantico
\ Per migliorare la nostra comprensione degli aspetti semantici delle istanze di oggetti che sono stati segmentati e mascherati all'interno delle nostre immagini, impieghiamo due modelli, CLIP [9] e DINOv2 [10], per derivare le rappresentazioni delle caratteristiche dalle immagini ritagliate di ciascun oggetto. Un modello addestrato esclusivamente con CLIP raggiunge una robusta comprensione semantica delle immagini ma non può discernere la profondità e i dettagli intricati all'interno di quelle immagini. D'altra parte, DINOv2 dimostra prestazioni superiori nella percezione della profondità ed eccelle nell'identificare relazioni sfumate a livello di pixel tra le immagini. Come Vision Transformer auto-supervisionato, DINOv2 può estrarre dettagli di caratteristiche sfumate senza fare affidamento su dati annotati, rendendolo particolarmente efficace nell'identificare relazioni spaziali e gerarchie all'interno delle immagini. Ad esempio, mentre il modello CLIP potrebbe faticare a differenziare tra due sedie di colori diversi, come rosso e verde, le capacità di DINOv2 consentono di fare tali distinzioni chiaramente. Per concludere, questi modelli catturano sia le caratteristiche semantiche che visive degli oggetti, che vengono successivamente utilizzate per confronti di similarità nello spazio 3D.
\ 
\ Un insieme di passaggi di pre-elaborazione viene implementato per l'elaborazione delle immagini con il modello DINOv2. Questi includono il ridimensionamento, il ritaglio centrale, la conversione dell'immagine in un tensore e la normalizzazione delle immagini ritagliate delineate dalle bounding box. L'immagine elaborata viene quindi inserita nel modello DINOv2 insieme alle etichette identificate dal modello RAM per generare le caratteristiche di embedding DINOv2. D'altra parte, quando si tratta del modello CLIP, il passaggio di pre-elaborazione comporta la trasformazione dell'immagine ritagliata in un formato tensore compatibile con CLIP, seguito dal calcolo delle caratteristiche di embedding. Questi embedding sono critici in quanto incapsulano gli attributi visivi e semantici degli oggetti, che sono cruciali per una comprensione completa degli oggetti nella scena. Questi embedding subiscono una normalizzazione basata sulla loro norma L2, che regola il vettore di caratteristiche a una lunghezza unitaria standardizzata. Questo passaggio di normalizzazione consente confronti coerenti ed equi tra diverse immagini.
\ Nella fase di implementazione di questa fase, iteriamo su ogni immagine all'interno dei nostri dati ed eseguiamo le procedure successive:
\ (1) L'immagine viene ritagliata alla regione di interesse utilizzando le coordinate della bounding box fornite dal modello Grounding DINO, isolando l'oggetto per un'analisi dettagliata.
\ (2) Generare embedding DINOv2 e CLIP per l'immagine ritagliata.
\ (3) Infine, gli embedding vengono memorizzati insieme alle maschere della sezione precedente.
\ Con questi passaggi completati, ora possediamo rappresentazioni dettagliate delle caratteristiche per ogni oggetto, arricchendo il nostro dataset per ulteriori analisi e applicazioni.
\
:::info Autori:
(1) Laksh Nanwani, International Institute of Information Technology, Hyderabad, India; questo autore ha contribuito in egual misura a questo lavoro;
(2) Kumaraditya Gupta, International Institute of Information Technology, Hyderabad, India;
(3) Aditya Mathur, International Institute of Information Technology, Hyderabad, India; questo autore ha contribuito in egual misura a questo lavoro;
(4) Swayam Agrawal, International Institute of Information Technology, Hyderabad, India;
(5) A.H. Abdul Hafez, Hasan Kalyoncu University, Sahinbey, Gaziantep, Turchia;
(6) K. Madhava Krishna, International Institute of Information Technology, Hyderabad, India.
:::
:::info Questo articolo è disponibile su arxiv sotto licenza CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\
Potrebbe anche piacerti

Bitcoin Consolida Sotto i $94K in Mezzo a una Domanda Debole, Guardando al Potenziale Rebound del 2026

Kevin Hassett Afferma l'Autonomia della Fed da Trump
