IVLMap Solves Robot Navigation By Mapping Individual Objects
Table of Links
Abstract and I. Introduction
II. Related Work
III. Method
IV. Experiment
V. Conclusion, Acknowledgements, and References
VI. Appendix
\
IV. EXPERIMENT
A. Experimental Setup
\ We employ the Habitat simulator [35] alongside the Matterport3D dataset [2] to assess performance in multi-object and spatial goal navigation tasks. Matterport3D is a comprehensive RGB-D dataset, featuring 10,800 panoramic views from 194,400 RGB-D images across 90 building-scale scenes, designed for advancing research in scene understanding indoor environments. For map creation in Habitat, we capture 13,506 RGB-D frames spanning six distinct scenes and document the camera pose for each frame, utilizing the cmu-exploration environment we established(Sec.IV-B). Due to computational constraints, our navigation experiments and the execution of the Large Language Model(Llama2) are conducted on separate servers. Llama2 operates on a server equipped with two NVIDIA RTX 3090 GPUs. As for IVLMap experiment, our experimental setup comprises an NVIDIA GeForce RTX 2080 Ti GPU with 12GB VRAM. Communication between these two servers is established using the Socket.IO[4] protocol.
\ Baseline: We assess IVLMap in comparison to three baseline methods, all employing visual-language models and demonstrating proficiency in zero-shot language-based navigation:
\
-
VLMap [5] seamlessly integrates language and visuals, autonomously constructing maps, and excels in indexing landmarks from human instructions, enhancing language-driven robots for intuitive communication in diverse navigation scenarios with open-vocabulary mapping and natural language indexing.
\
-
Clip on Wheels (CoW) [30] achieves language-driven object navigation by creating a target-specific saliency map using CLIP and GradCAM [36]. It involves applying a threshold to saliency values, extracting a segmentation mask, and planning the navigation path based on this information.
\
-
The CLIP-features-based map (CLIP Map) serves as an ablative baseline, projecting CLIP visual features onto the environment’s feature map and generating object category masks through thresholding the feature similarity.
\ Evaluation Metrics: Similar to previous methods [5], [37] in VLN literature, we use the standard Success Ratemetric(SR) to measure the success ratio for the navigation task. We assessed our IVLMap’s effectiveness by (i) presenting multiple navigation targets and (ii) using natural language commands. Success is defined as the agent stopping within a predefined distance threshold from the ground truth object.
\ B. Dataset acquisition and 3D Reconstruction
\ To construct a map in visual and language navigation tasks, it is crucial to acquire RGB images, depth information, and pose data from the robot or its agent while it is in motion. Common datasets on the internet, such as Matterport3D [2], Scannet [38], KITTI [39], may not be directly applicable to our scenario. Therefore, we undertook the task of collecting a dataset tailored to our specific requirements. Our data collection efforts were conducted in both virtual and real(Appendix.C) environments to ensure comprehensive coverage.
\ 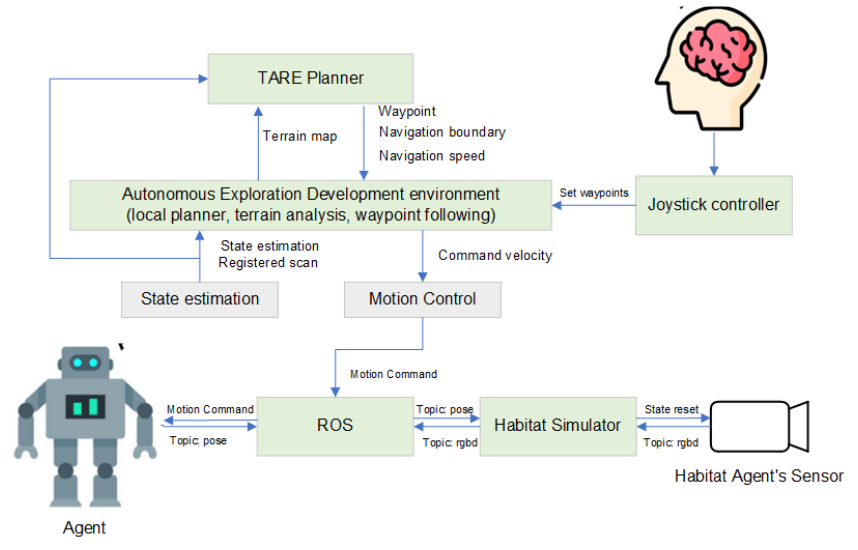
\ Interactive Data Collection in Virtual Habitats and CMU-Exploration Environment. CMU-Exploration [40], designed for autonomous navigation system development, offers
\ various simulation environments and modules. Combined with the Habitat Simulator [35], it forms a platform where users develop and deploy navigation systems for real robots. Our interactive data collection system in this virtual environment utilizes CMU-Exploration’s Joystick and Visualization Tools for waypoint setting. Waypoints undergo local planning, terrain and radar analysis, and state estimation, generating control commands for ROS-based robot motion. Simultaneously, robot pose data is sent to the Habitat simulator, providing RGB, depth, and pose information for direct sensor control. See Fig. 8 for an overview.
\ Compared to other black-box data collection methods in the Habitat simulator, where predefined routes or exploration algorithms are used, this approach offers strong controllability. It allows tailored responses to the environment, enabling the collection of fewer data points while achieving superior reconstruction results. For the same scene in Matterport3D, our approach achieves comparable results to the VLMap’s original authors while reducing the data volume by approximately 8%. In certain areas, the reconstruction performance even surpasses that of the original authors. To compare the results, refer to Fig.5(a) and Fig.5(b), for more detailed results of our 3D reconstruction bird’s-eye view, please refer to Appendix D.
\ 
\ C. Multi-Object Navigation with given subgoals
\ To assess the localization and navigation performance of IVLMap, we initially conducted navigation experiments with given subgoals. In the navigation experiments conducted in the four scenes of the Matterport dataset, we curated multiple navigation tasks for each scene. Each navigation task comprises four subgoals. The robot is instructed to sequentially navigate to each subgoal of each task. We use the invocation of the ”stop” function by the robot as a criterion. If the robot calls the ”stop” function and its distance to the target is less than a threshold (set to 1 meter in our case), it is considered successful navigation to that subgoal. Successful completion of a navigation task is achieved when the robot successfully navigates to all four subgoals in sequence. It is noteworthy that we provided instance information of objects in the given subgoals to examine the effectiveness of our constructed IVLMap.
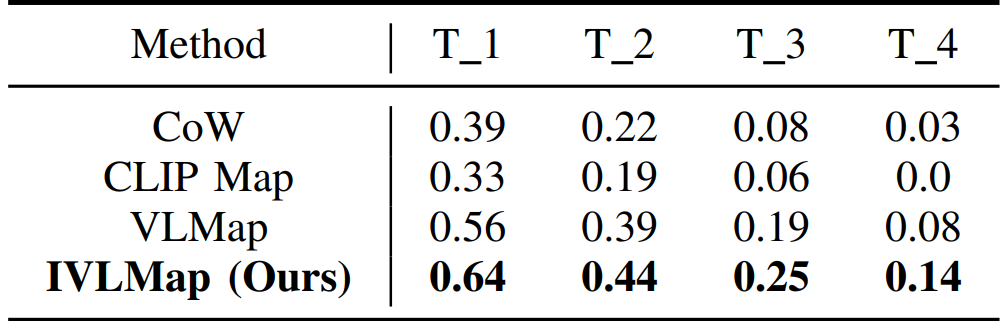
\ \ Our observations(Table.I) indicate that our approach outperforms all other baselines. It exhibits a slight improvement
\ 
\ in navigation performance compared to VLMap, while significantly surpassing the performance of CoW and CLIP Map. VLMap achieves zero-shot navigation by smoothly performing precise localization of landmarks. However, this baseline has limitations as it can only navigate to the nearest category to the robot agent, lacking the capability for precise instantiation navigation. As illustrated in the comparisons between Fig.6(a) and Fig.6(b), our proposed IVLMap incorporates instantiation information for each landmark, enabling precise instantiation navigation tasks. Consequently, the final navigation performance is significantly enhanced. During specific localization, our approach involves initially identifying the approximate region of the landmark from the U and V matrices of IVLMap M(Sec.III-A). Subsequently, further refinement is conducted using VLMap, optimizing the performance of VLMap and resulting in a significant improvement in navigation accuracy
\ 
\ 
\ D. Zero-Shot Instance Level Object Goal Navigation from Natural Language
\ In these experiments, we assess IVLMaps’ performance in comparison to alternative baselines concerning zero-shot instance-level object goal navigation initiated by natural language instructions. Our benchmark comprises 36 trajectories across four scenes, each accompanied by manually provided language instructions for evaluation purposes. In each language instruction, we provide instantiation and color information for navigation subgoals using natural language, such as ”the first yellow sofa”, ”in between the chair and the sofa” or ”east of the red table.” Leveraging LLM, the robot agent extracts this information for localization and navigation. Each trajectory comprises four subgoals, and successful navigation to the proximity of a subgoal within a threshold range (set at 1m) is considered a success.
\ 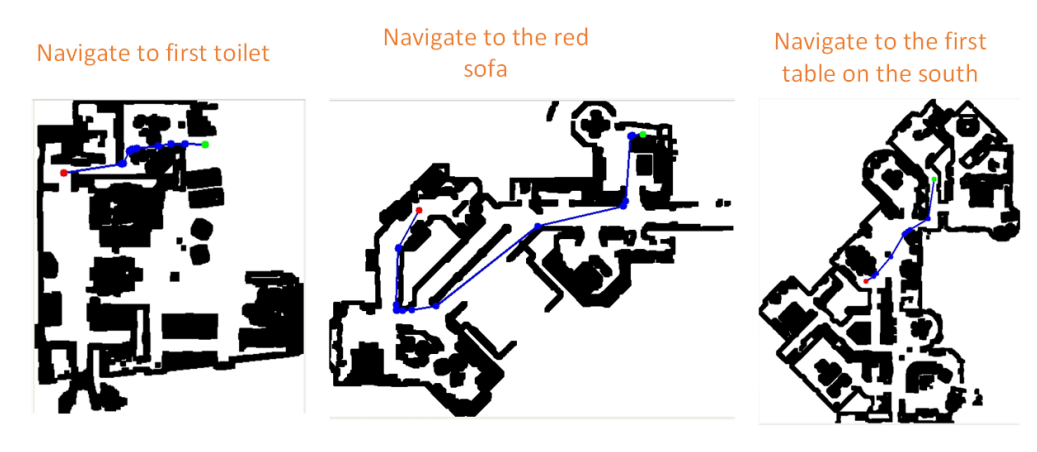
\ Analysis of Table.II reveals that in zero-shot level object goal navigation, our navigation accuracy is hardly affected. This is attributed to the initial parsing of natural language instructions using LLM, enabling precise extraction of physical attributes, ensuring robust performance in navigation. Moreover, as depicted in partial trajectory schematics of navigation tasks in Fig.7, our IVLMap achieves precise instance-level object navigation globally, a capability unmatched by other baselines.
V. CONCLUSION
In this study, we introduce the Instance Level Visual Language Map (IVLMap), elevating navigation precision through instance-level and attribute-level semantic language instructions. Our approach is designed to enhance applicability in real-life scenarios, showing promising results in initial realworld robot applications. However, the mapping performance in dynamic environments requires improvement, prompting the exploration of real-time navigation using laser scanners. Our future goals include advancing towards 3D semantic maps to enable dynamic perception of object height, contributing to more accurate spatial navigation. Ongoing research efforts will focus on addressing these challenges.
ACKNOWLEDGMENT
The work is supported by the National Natural Science Foundation of China (no. 61601112). It is also supported by the Fundamental Research Funds for the Central Universities and DHU Distinguished Young Professor Program.
REFERENCES
[1] Z. Fu, T. Z. Zhao, and C. Finn, “Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,” in arXiv, 2024.
\ [2] P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sunderhauf, ¨ I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683.
\ [3] J. Gu, E. Stefani, Q. Wu, J. Thomason, and X. E. Wang, “Vision-andlanguage navigation: A survey of tasks, methods, and future directions,” arXiv preprint arXiv:2203.12667, 2022.
\ [4] D. Shah, B. Osinski, S. Levine et al., “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” in Conference on Robot Learning. PMLR, 2023, pp. 492–504.
\ [5] C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 10 608–10 615.
\ [6] Y. Qi, Q. Wu, P. Anderson, X. Wang, W. Y. Wang, C. Shen, and A. v. d. Hengel, “Reverie: Remote embodied visual referring expression in real indoor environments,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9982–9991.
\ [7] F. Zhu, X. Liang, Y. Zhu, Q. Yu, X. Chang, and X. Liang, “Soon: Scenario oriented object navigation with graph-based exploration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 689–12 699.
\ [8] Z. Wang, J. Li, Y. Hong, Y. Wang, Q. Wu, M. Bansal, S. Gould, H. Tan, and Y. Qiao, “Scaling data generation in vision-and-language navigation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12 009–12 020.
\ [9] K. He, Y. Huang, Q. Wu, J. Yang, D. An, S. Sima, and L. Wang, “Landmark-rxr: Solving vision-and-language navigation with finegrained alignment supervision,” Advances in Neural Information Processing Systems, vol. 34, pp. 652–663, 2021.
\ [10] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
\ [11] K. Fukushima, “Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position,” Biological cybernetics, vol. 36, no. 4, pp. 193–202, 1980.
\ [12] P. Estefo, J. Simmonds, R. Robbes, and J. Fabry, “The robot operating system: Package reuse and community dynamics,” Journal of Systems and Software, vol. 151, pp. 226–242, 2019.
\ [13] R. F. Salas-Moreno, R. A. Newcombe, H. Strasdat, P. H. Kelly, and A. J. Davison, “Slam++: Simultaneous localisation and mapping at the level of objects,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 1352–1359.
\ [14] J. McCormac, R. Clark, M. Bloesch, A. Davison, and S. Leutenegger, “Fusion++: Volumetric object-level slam,” in 2018 international conference on 3D vision (3DV). IEEE, 2018, pp. 32–41.
\ [15] B. Chen, F. Xia, B. Ichter, K. Rao, K. Gopalakrishnan, M. S. Ryoo, A. Stone, and D. Kappler, “Open-vocabulary queryable scene representations for real world planning,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 11 509–11 522.
\ [16] S.-H. Zhang, R. Li, X. Dong, P. Rosin, Z. Cai, X. Han, D. Yang, H. Huang, and S.-M. Hu, “Pose2seg: Detection free human instance segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 889–898.
\ [17] Y. Lee and J. Park, “Centermask: Real-time anchor-free instance segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 13 906–13 915.
\ [18] Y. Long, X. Li, W. Cai, and H. Dong, “Discuss before moving: Visual language navigation via multi-expert discussions,” arXiv preprint arXiv:2309.11382, 2023.
\ [19] Z. Jia, K. Yu, J. Ru, S. Yang, and S. Coleman, “Vital information matching in vision-and-language navigation,” Frontiers in Neurorobotics, vol. 16, p. 1035921, 2022.
\ [20] A. B. Vasudevan, D. Dai, and L. Van Gool, “Talk2nav: Long-range vision-and-language navigation with dual attention and spatial memory,” International Journal of Computer Vision, vol. 129, pp. 246–266, 2021.
\ [21] P. Chen, D. Ji, K. Lin, R. Zeng, T. Li, M. Tan, and C. Gan, “Weaklysupervised multi-granularity map learning for vision-and-language navigation,” Advances in Neural Information Processing Systems, vol. 35, pp. 38 149–38 161, 2022.
\ [22] J. Krantz, S. Banerjee, W. Zhu, J. Corso, P. Anderson, S. Lee, and J. Thomason, “Iterative vision-and-language navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14 921–14 930.
\ [23] G. Zhou, Y. Hong, and Q. Wu, “Navgpt: Explicit reasoning in visionand-language navigation with large language models,” arXiv preprint arXiv:2305.16986, 2023.
\ [24] R. Schumann, W. Zhu, W. Feng, T.-J. Fu, S. Riezler, and W. Y. Wang, “Velma: Verbalization embodiment of llm agents for vision and language navigation in street view,” arXiv preprint arXiv:2307.06082, 2023.
\ [25] S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “Chatgpt for robotics: Design principles and model abilities. 2023,” Published by Microsoft, 2023.
\ [26] D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: An embodied multimodal language model,” arXiv preprint arXiv:2303.03378, 2023.
\ [27] B. Li, K. Weinberger, S. Belongie, V. Koltun, and R. Ranftl, “Languagedriven semantic segmentation,” 2023.
\ [28] P. P. Ray, “Chatgpt: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope,” Internet of Things and Cyber-Physical Systems, 2023.
\ [29] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
\ [30] S. Y. Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song, “Clip on wheels: Zero-shot object navigation as object localization and exploration,” arXiv preprint arXiv:2203.10421, vol. 3, no. 4, p. 7, 2022.
\ [31] M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman et al., “Do as i can, not as i say: Grounding language in robotic affordances,” arXiv preprint arXiv:2204.01691, 2022.
\ [32] A. Zeng, M. Attarian, B. Ichter, K. Choromanski, A. Wong, S. Welker, F. Tombari, A. Purohit, M. Ryoo, V. Sindhwani et al., “Socratic models: Composing zero-shot multimodal reasoning with language,” arXiv preprint arXiv:2204.00598, 2022.
\ [33] J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500.
\ [34] E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “Gptq: Accurate post-training quantization for generative pre-trained transformers,” arXiv preprint arXiv:2210.17323, 2022.
\ [35] M. Savva, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik et al., “Habitat: A platform for embodied ai research,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347.
\ [36] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 618–626.
\ [37] R. Schumann and S. Riezler, “Analyzing generalization of vision and language navigation to unseen outdoor areas,” arXiv preprint arXiv:2203.13838, 2022.
\ [38] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5828–5839.
\ [39] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,” The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, 2013.
\ [40] C. Cao, H. Zhu, F. Yang, Y. Xia, H. Choset, J. Oh, and J. Zhang, “Autonomous exploration development environment and the planning algorithms,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 8921–8928.
\
:::info Authors:
(1) Jiacui Huang, Senior, IEEE;
(2) Hongtao Zhang, Senior, IEEE;
(3) Mingbo Zhao, Senior, IEEE;
(4) Wu Zhou, Senior, IEEE.
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
[4] Socket.IO is a real-time communication protocol built on WebSocket, providing event-driven bidirectional communication for seamless integration of interactive features in web applications, official website https://socket.io/.
You May Also Like

Developers of Altcoin Traded on Binance Reveal Reason for Major Price Drop – “Legal Process Has Begun”

Gate Alpha is launching its 113th round of points airdrops. Holders of the corresponding points can be among the first to receive 0.9 or 4.5 TRUMP.