

Ekstrakcja semantyczna typu open-set: Pipeline Grounded-SAM, CLIP i DINOv2
Spis linków
Abstrakt i 1 Wprowadzenie
-
Prace powiązane
2.1. Nawigacja oparta na wizji i języku
2.2. Semantyczne rozumienie sceny i segmentacja instancji
2.3. Rekonstrukcja sceny 3D
-
Metodologia
3.1. Zbieranie danych
3.2. Informacje semantyczne typu open-set z obrazów
3.3. Tworzenie reprezentacji 3D typu open-set
3.4. Nawigacja sterowana językiem
-
Eksperymenty
4.1. Ocena ilościowa
4.2. Wyniki jakościowe
-
Wnioski i przyszłe prace, oświadczenie o ujawnieniu i referencje
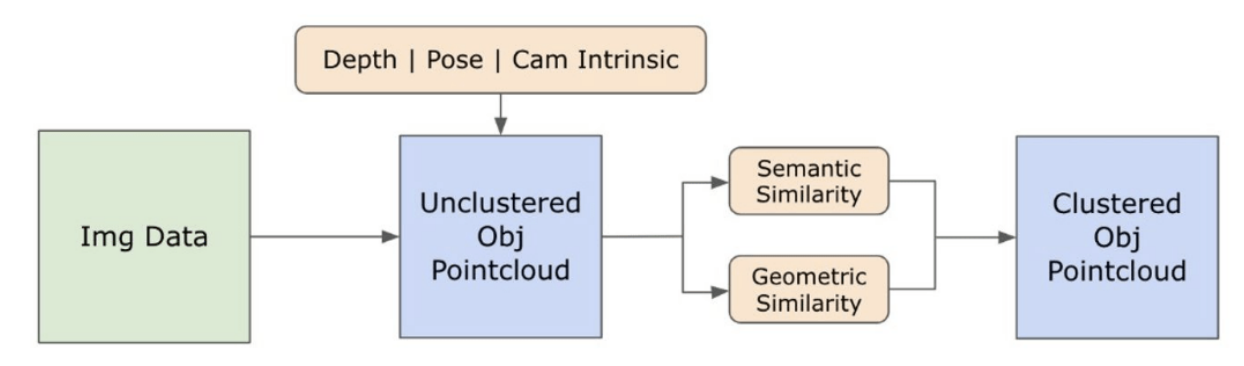
3.2. Informacje semantyczne typu open-set z obrazów
\ 3.2.1. Wykrywanie masek semantycznych i instancji typu open-set
\ Niedawno wydany model Segment Anything (SAM) [21] zyskał znaczną popularność wśród badaczy i praktyków przemysłowych dzięki swoim zaawansowanym możliwościom segmentacji. Jednakże SAM ma tendencję do tworzenia nadmiernej liczby masek segmentacyjnych dla tego samego obiektu. Aby rozwiązać ten problem, w naszej metodologii przyjmujemy model Grounded-SAM [32]. Proces ten obejmuje generowanie zestawu masek w trzech etapach, jak pokazano na Rysunku 2. Początkowo tworzony jest zestaw etykiet tekstowych przy użyciu modelu Recognizing Anything (RAM) [33]. Następnie, przy użyciu modelu Grounding DINO [25], tworzone są ramki ograniczające odpowiadające tym etykietom. Obraz i ramki ograniczające są następnie wprowadzane do SAM w celu wygenerowania niezależnych od klasy masek segmentacyjnych dla obiektów widocznych na obrazie. Poniżej przedstawiamy szczegółowe wyjaśnienie tego podejścia, które skutecznie łagodzi problem nadmiernej segmentacji poprzez włączenie semantycznych informacji z RAM i Grounding-DINO.
\ Model RAM [33] przetwarza wejściowy obraz RGB, aby wygenerować semantyczne etykietowanie obiektów wykrytych na obrazie. Jest to solidny model podstawowy do tagowania obrazów, wykazujący niezwykłe zdolności zero-shot w dokładnym identyfikowaniu różnych powszechnych kategorii. Wynik tego modelu kojarzy każdy obraz wejściowy z zestawem etykiet opisujących kategorie obiektów na obrazie. Proces rozpoczyna się od uzyskania dostępu do obrazu wejściowego i przekształcenia go do przestrzeni kolorów RGB, następnie zmienia jego rozmiar, aby dopasować go do wymagań wejściowych modelu, a na końcu przekształca go w tensor, czyniąc go kompatybilnym z analizą przez model. Następnie model RAM generuje etykiety lub tagi, które opisują różne obiekty lub cechy obecne na obrazie. Stosowany jest proces filtracji w celu udoskonalenia wygenerowanych etykiet, który obejmuje usunięcie niechcianych klas z tych etykiet. W szczególności odrzucane są nieistotne tagi, takie jak "ściana", "podłoga", "sufit" i "biuro", wraz z innymi predefiniowanymi klasami uznanymi za niepotrzebne w kontekście badania. Dodatkowo, ten etap pozwala na rozszerzenie zestawu etykiet o wszelkie wymagane klasy, które nie zostały początkowo wykryte przez model RAM. Na koniec wszystkie istotne informacje są agregowane w ustrukturyzowanym formacie. W szczególności każdy obraz jest katalogowany w słowniku img_dict, który rejestruje ścieżkę obrazu wraz z zestawem wygenerowanych etykiet, zapewniając w ten sposób dostępne repozytorium danych do dalszej analizy.
\ Po oznaczeniu obrazu wejściowego wygenerowanymi etykietami, przepływ pracy postępuje poprzez wywołanie modelu Grounding DINO [25]. Model ten specjalizuje się w ugruntowywaniu fraz tekstowych do określonych regionów w obrazie, skutecznie wyznaczając obiekty docelowe za pomocą ramek ograniczających. Proces ten identyfikuje i przestrzennie lokalizuje obiekty w obrazie, tworząc podstawę do bardziej szczegółowych analiz. Po zidentyfikowaniu i zlokalizowaniu obiektów za pomocą ramek ograniczających, stosowany jest model Segment Anything (SAM) [21]. Główną funkcją modelu SAM jest generowanie masek segmentacyjnych dla obiektów w tych ramkach ograniczających. Dzięki temu SAM izoluje poszczególne obiekty, umożliwiając bardziej szczegółową i specyficzną dla obiektu analizę poprzez skuteczne oddzielenie obiektów od ich tła i od siebie nawzajem w obrazie.
\ Na tym etapie instancje obiektów zostały zidentyfikowane, zlokalizowane i wyizolowane. Każdy obiekt jest identyfikowany za pomocą różnych szczegółów, w tym współrzędnych ramki ograniczającej, opisowego terminu dla obiektu, prawdopodobieństwa lub wyniku pewności istnienia obiektu wyrażonego w logitach oraz maski segmentacyjnej. Ponadto każdy obiekt jest powiązany z cechami osadzenia CLIP i DINOv2, których szczegóły są omówione w następnej podsekcji.
\ 3.2.2. Ekstrakcja osadzenia semantycznego
\ Aby poprawić nasze zrozumienie semantycznych aspektów instancji obiektów, które zostały segmentowane i zamaskowane w naszych obrazach, stosujemy dwa modele, CLIP [9] i DINOv2 [10], aby uzyskać reprezentacje cech z przyciętych obrazów każdego obiektu. Model trenowany wyłącznie z CLIP osiąga solidne semantyczne zrozumienie obrazów, ale nie może rozróżnić głębi i skomplikowanych szczegółów w tych obrazach. Z drugiej strony, DINOv2 wykazuje lepszą wydajność w percepcji głębi i doskonale identyfikuje niuansowe relacje na poziomie pikseli między obrazami. Jako samonadzorowany Vision Transformer, DINOv2 może wyodrębnić niuansowe szczegóły cech bez polegania na oznaczonych danych, co czyni go szczególnie skutecznym w identyfikowaniu relacji przestrzennych i hierarchii w obrazach. Na przykład, podczas gdy model CLIP może mieć trudności z rozróżnieniem dwóch krzeseł o różnych kolorach, takich jak czerwony i zielony, możliwości DINOv2 pozwalają na wyraźne dokonanie takich rozróżnień. Podsumowując, modele te przechwytują zarówno semantyczne, jak i wizualne cechy obiektów, które są później wykorzystywane do porównań podobieństwa w przestrzeni 3D.
\ 
\ Zestaw kroków wstępnego przetwarzania jest implementowany do przetwarzania obrazów za pomocą modelu DINOv2. Obejmują one zmianę rozmiaru, przycinanie centralne, konwersję obrazu do tensora i normalizację przyciętych obrazów wyznaczonych przez ramki ograniczające. Przetworzony obraz jest następnie wprowadzany do modelu DINOv2 wraz z etykietami zidentyfikowanymi przez model RAM w celu wygenerowania cech osadzenia DINOv2. Z drugiej strony, w przypadku modelu CLIP, krok wstępnego przetwarzania obejmuje przekształcenie przyciętego obrazu do formatu tensora kompatybilnego z CLIP, a następnie obliczenie cech osadzenia. Te osadzenia są kluczowe, ponieważ zawierają wizualne i semantyczne atrybuty obiektów, które są niezbędne do kompleksowego zrozumienia obiektów w scenie. Te osadzenia przechodzą normalizację opartą na ich normie L2, która dostosowuje wektor cech do standardowej długości jednostkowej. Ten krok normalizacji umożliwia spójne i uczciwe porównania między różnymi obrazami.
\ W fazie implementacji tego etapu iterujemy przez każdy obraz w naszych danych i wykonujemy następujące procedury:
\ (1) Obraz jest przycinany do obszaru zainteresowania przy użyciu współrzędnych ramki ograniczającej dostarczonych przez model Grounding DINO, izolując obiekt do szczegółowej analizy.
\ (2) Generujemy osadzenia DINOv2 i CLIP dla przyciętego obrazu.
\ (3) Na koniec osadzenia są przechowywane wraz z maskami z poprzedniej sekcji.
\ Po zakończeniu tych kroków posiadamy teraz szczegółowe reprezentacje cech dla każdego obiektu, wzbogacając nasz zestaw danych do dalszej analizy i zastosowania.
\
:::info Autorzy:
(1) Laksh Nanwani, Międzynarodowy Instytut Technologii Informacyjnych, Hyderabad, Indie; ten autor przyczynił się w równym stopniu do tej pracy;
(2) Kumaraditya Gupta, Międzynarodowy Instytut Technologii Informacyjnych, Hyderabad, Indie;
(3) Aditya Mathur, Międzynarodowy Instytut Technologii Informacyjnych, Hyderabad, Indie; ten autor przyczynił się w równym stopniu do tej pracy;
(4) Swayam Agrawal, Międzynarodowy Instytut Technologii Informacyjnych, Hyderabad, Indie;
(5) A.H. Abdul Hafez, Uniwersytet Hasan Kalyoncu, Sahinbey, Gaziantep, Turcja;
(6) K. Madhava Krishna, Międzynarodowy Instytut Technologii Informacyjnych, Hyderabad, Indie.
:::
:::info Ten artykuł jest dostępny na arxiv na licencji CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\
Możesz także polubić
Shiba Inu Może Ponownie Wzrosnąć 25-krotnie, Jednak Perspektywy Ozak AI na 2026 Rok Wyglądają Znacznie Bardziej Wybuchowo

Top 10 tokenów do zgromadzenia przed 2026 rokiem z IPO Genie ($IPO) wiodącym w dziedzinie użyteczności AI
