

文章作者、来源:AI吹哨兵 一个AI研究员做了一个测试 把一篇文章翻译成9种语言,喂进六家模型的分词器 以英文token数为基准,看各语言消耗多少 中文结果出来了,Claude是六家里最贵的: Kimi比英文还省,Claude却多花65%成本 同一段中文,Kimi只用0.81倍token,Claude要用1.65倍 差文章作者、来源:AI吹哨兵 一个AI研究员做了一个测试 把一篇文章翻译成9种语言,喂进六家模型的分词器 以英文token数为基准,看各语言消耗多少 中文结果出来了,Claude是六家里最贵的: Kimi比英文还省,Claude却多花65%成本 同一段中文,Kimi只用0.81倍token,Claude要用1.65倍 差
AI也有地域歧视,Claude 用中文成本贵出 65%
如需对本内容提供反馈或相关疑问,请通过邮箱 crypto.news@mexc.com 联系我们。
文章作者、来源:AI吹哨兵
一个AI研究员做了一个测试
把一篇文章翻译成9种语言,喂进六家模型的分词器
以英文token数为基准,看各语言消耗多少
中文结果出来了,Claude是六家里最贵的:
Kimi比英文还省,Claude却多花65%成本
同一段中文,Kimi只用0.81倍token,Claude要用1.65倍
差距不是来自模型能力,是来自AI设计的分词器
Kimi和Qwen的分词器针对中文做过优化,一个汉字对应更少的token
Claude的分词器以英文为核心设计,中文字符被切得更碎,更加消耗token
中文还不是最惨的
同一批测试,印地语和阿拉伯语的数据:
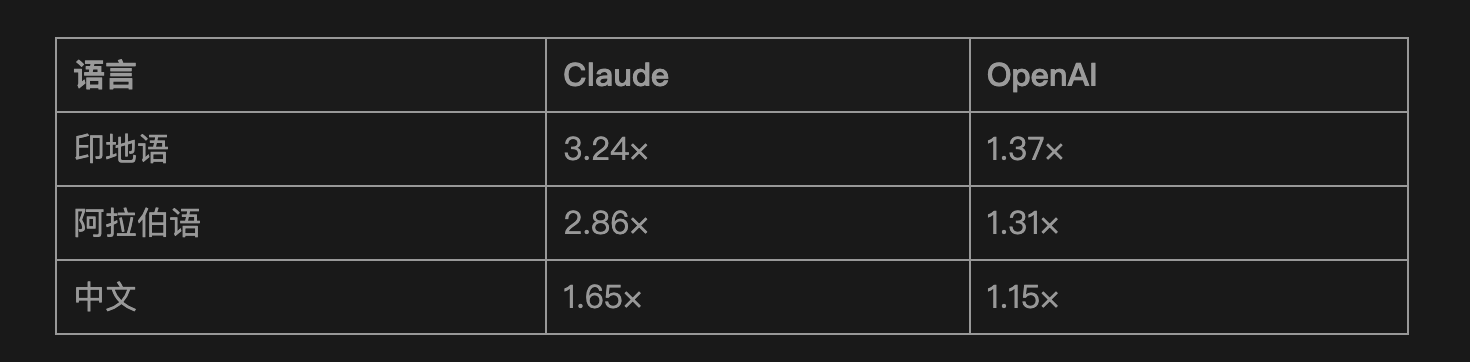 印地语有超过6亿母语使用者,每次调用Claude都在多付3倍以上的钱
印地语有超过6亿母语使用者,每次调用Claude都在多付3倍以上的钱
用Claude做中文产品,成本直接受影响
以一个每天处理10万字中文内容的应用为例:
• 用OpenAI:按1.15倍计费
• 用Claude:按1.65倍计费
• 差距:同等预算下,Claude能处理的内容量少30%
长文档分析、批量翻译、中文客服系统
凡是中文调用量大的场景,这个差距都会被放大
不过Anthropic目前没有公开回应这个问题


免责声明: 本网站转载的文章均来源于公开平台,仅供参考。这些文章不代表 MEXC 的观点或意见。所有版权归原作者所有。如果您认为任何转载文章侵犯了第三方权利,请联系 crypto.news@mexc.com 以便将其删除。MEXC 不对转载文章的及时性、准确性或完整性作出任何陈述或保证,并且不对基于此类内容所采取的任何行动或决定承担责任。转载材料仅供参考,不构成任何商业、金融、法律和/或税务决策的建议、认可或依据。
您可能也会喜欢

欧洲央行滞胀风险使政策路径复杂化:荷兰国际集团警告前方抉择艰难
BitcoinWorld 欧洲央行滞胀风险使政策路径复杂化:荷兰国际集团警告前方面临艰难抉择 欧洲央行面临日益加剧的滞胀风险,
分享
bitcoinworld2026/05/01 01:35

「别再跟我说话了!」共和党议员对TMZ记者爆粗口强行转移话题
众议员丹·穆泽(Dan Meuser)周四在接受TMZ采访时情绪失控,此前一名记者就国会即将到来的10天休会期向他施压,而目前有关拨款问题的僵局仍悬而未决。
分享
Rawstory2026/05/01 01:28

菲律宾东盟轮值主席国:绕道而行的积极意义
当菲律宾于一月正式担任东盟轮值主席国时,它公布了三个希望在年内实现的跨支柱目标——安全锚点
分享
Bworldonline2026/05/01 00:01